How to detect shared scripts when interviewing candidates

Detecting Deceptive Interview Behaviours
Applying for a job is often compared to an audition. You invest time and energy to reflect, plan, and prepare, so that when the lights come up you present your strengths in the best possible way, while minimizing any scrutiny on your perceived weaknesses.
And this is human nature. We generally want to be perceived as capable and likable, and in a high-stakes situation, such as going through a hiring process, this will be at the forefront of our minds.
However, where this starts to breakdown is as we move along the continuum of preparedness from generally accepted methods, such as researching the company, reflecting on your work history, and seeking tips and guidance from your more experienced friends and relatives, to extreme levels of faking, which is what the academic community generously calls what most would refer to as cheating, when we answer dishonestly, use 3rd party tools, or pass someone else’s work of as our own.
This undermines what we are trying to achieve – we want to understand if a candidate is the right person for a role. And so it is the point at which an applicant’s score no longer reflects who they are that we are most concerned with.
The State of ‘Cheating’
Cheating or faking in the pre-employment space has yielded a wealth of research, far too abundant to comprehensively summarize here (I’d recommend Griffith & Peterson, 2006, for a deeper dive). But a significant portion of the research focuses on 3 key areas – can we detect or control for cheating, how prevalent is cheating, and how impactful is cheating. Generally, cheating in pre-employment tests is not as consistent or common as we might assume (based on comparing scores in high stakes vs. low stakes settings, for example), and there are various measures to detect cheating on different types of tests (albeit to varying degrees of efficacy).
The third component of cheating, around how impactful it is, is also highly interesting. An often stated (although still challenged) perspective is that faking good, ie. manipulating your answers to be flattering yet less true, is still signaling something beneficial. The logical argument is that in order to fake good, you must at least understand what ‘good’ looks like for the role or company, and therefore you’ll be able to at least act it better than the person who doesn’t understand what good looks like.
However, the evidence for this is similar to the prevalence of cheating, with results varying significantly across studies (Lanyon & Goodstein, 2016). This also works solely on the assumption that understanding what ‘good’ looks like and how to portray it came from the applicant, and not from a 3rd party who did the hard work for them.
And that is precisely what we are interested in here.
Shared Script Detection
With a significant part of HireVue’s assessment offering based on scoring open-ended interviews, we wanted to explore the three core concerns around cheating: can we detect it, how prevalent is it, and how impactful is it. And we wanted to focus on the concept floated above – that being less concerned around faking good only holds true if it’s the candidate’s own work. So we landed on exploring where it is possible to identify when a candidate is using someone else’s work to answer a video assessment with the intention to achieve a better score. That is, can we detect a shared script?.
We loosely define “shared script detection” as, “When one or more candidates have provided responses with detectable similarities that are unlikely due to chance, suggesting either they have collaborated significantly on their response or used a 3rd party script and/or set of notes.” We are not then concerned with when the same person has used the same response in different interviews, or if a candidate has prepared their own notes that they read from. What we are looking for is a level of similarity in response between two candidates that cannot be coincidental.
Now, publicizing the approach in too great a detail would be folly, as this would only invite creative ways to get around it. However, we are able to apply a statistical technique (let’s call it our Similarity Score) to compare the similarity of two responses, that is robust to efforts that respondents might make to hide what they are doing. It’s reasonable to assume that more thoughtful individuals would at least tweak the notes or script to better align with their own work and educational experience, and also make it less obvious that this isn’t an independent response. The output of this is a score from 0 to 1 for each comparison (ie. response from Candidate A to Candidate B), where a score that is closer to 1 means a higher level of similarity and therefore likelihood of a communal script or set of notes.
We also then sought to test this in a couple of large samples, focusing on areas where we hoped we would be more likely to find the sharing of scripts. For example, we chose Graduate hiring for two high profile brands, one in a geography where this is perceived to be more common, and where there were question sets that had remained unchanged for a couple of years. For each company, we explored the similarity of responses to each of two questions, giving us four samples in total.
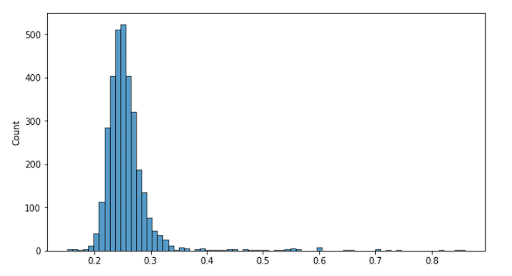
To help understand what we found, we can visualize this in the following histogram. The Y axis is the number of respondents whose highest Similarity Score (ie. when compared to all other respondents) is represented on the X axis. So we can see at the peak, about 500 respondents’ highest level of similarity with someone else was .25, with slightly more (maybe 510) hitting .26. We see a relatively normal distribution of scores centered around these scores. And this is to be expected, as if you ask 3000 people to respond to the same question, you’ll inevitably get some commonalities in terms of what they talk about.
However, as we progress to the far right of the chart, it starts to get interesting. As we can manually review the responses outside of this distribution, and see as they go from being totally unrelated, to increasingly similar, to being almost identical in terms of content. After extensive review, we found that the degree of similarity between a pair of responses scoring .4 or greater could almost certainly not be coincidental, and so we defined this as the point above which we deemed sharing of a script (or extensive notes) must have occurred. We note that ‘cheating’ is used as a black and white term throughout here – whereas in fact there are of course shades of gray, from preparing heavily with a friend up to reciting a script you found online. We therefore set the threshold intentionally high to avoid the risk of false positives.
So – can we detect cheating?
Yes.
For pairs of individuals scoring closer to 1, these are where the responses are almost identical, and are clearly being read word-for-word from a script. Visual inspection confirms that some do not even attempt to hide this. However, pairs of individuals scoring closer to .4 have clearly made efforts to mask what they are doing (changing words, such as company names or departments, full phrases, and adding filler sentences, or even slightly shifting the theme of discussion), but when reviewed side-by-side by a human, it is clear that the similarities in response can not be by chance.
How prevalent is cheating?
Pretty rare (at least this type of cheating).
We had four samples in total. For Customer A, we compared 3268 responses to Question 1 to each other, and 3270 responses to Question 2. For Customer B, we compared 2110 responses to Question 1, and 2110 responses for Question 2.
Ignoring where it was the same candidate twice, which generally accounted for the highest scores, and using our threshold of a Similarity Score of .4, we can see the count of individuals who we are confident shared a script below:
| Question 1 | Question 2 | |
|---|---|---|
| Customer A | 35 out of 3268 responses (1.07%) | 19 out of 3270 responses (0.58%) |
| Customer B | 9 out of 2110 (0.43%) | 7 out of 2110 (0.33%) |
So in total, only 0.65% of almost 11,000 question responses showed evidence of sharing a script or set of notes between candidates.
How impactful is cheating?
Not that impactful.
If we consider the assessment scores for the groups of individuals above, those exceeding the threshold had a mean score of 23% and 44% for Customer A, and 45% and 37% for Customer B. Considering that scores on our models are normalized to have a mean of 50%, we can see that these individuals typically scored below the average. Many of these individuals would be unlikely to progress to the next stage, as customers would likely have progressed those with above average scores. Therefore the impact of false positives, ie. underqualified candidates who score highly and therefore move forward, is limited.
Conclusion
While only focusing on one way in which individuals may attempt to cheat their HireVue assessment, we’ve been able to refine a technique to detect this at scale. With many customers having tens, if not hundreds of thousands of candidates apply for their roles, it is not feasible to expect recruiters to pick up on these similarities as they review candidate interviews.
While noting that the prevalence of shared scripts is not particularly high, nor are those that engage with it particularly effective, it provides further opportunity for us to ensure that applicants’ assessment scores are truly reflective of their ability, therefore enabling organizations to make better hiring decisions.
Honz, K., Kiewra, K. A., & Yang, Y. (2010). Cheating perceptions and prevalence across academic settings. Mid-Western Educational Researcher, 23(2), 10-17.
Griffith, R. L., & Peterson, M. H. (Eds.). (2006). A closer examination of applicant faking behavior. IAP.
Lanyon, R. I., & Goodstein, L. D. (2016). Pre-employment good impression and subsequent job performance. Journal of Managerial Psychology, 31(2), 346-358.


